
Tabella dei contenuti
L’importanza del crawl budget nella SEO è un aspetto cruciale da considerare per ottimizzare la visibilità online di un sito web. Ma cosa significa esattamente il termine “crawl budget” e come influisce sull’indicizzazione dei motori di ricerca, in particolare su Google?
Il crawl budget è il numero di pagine che il crawler di un motore di ricerca come Google o Bing può scansionare in un dato periodo di tempo.
Le dimensioni e la frequenza di aggiornamento dei contenuti di un sito web giocano un ruolo fondamentale nella gestione ottimale delle scansioni effettuate da Google, un aspetto cruciale per garantire una buona visibilità nelle pagine di ricerca. Questa guida esamina le strategie avanzate per massimizzare l’efficienza della scansione su siti di grandi dimensioni o con aggiornamenti frequenti.
Crawl budget: a chi interessa
Come dice la guida Google sul Crawl Budget, l’ottimizzazione della scansione di Google è particolarmente rilevante per tre categorie principali di siti web:
- Siti di grandi dimensioni come editori online (oltre un milione di pagine univoche) con contenuti che cambiano con una certa frequenza (una volta a settimana).
- Siti di medie o grandi dimensioni come e-commerce di grandi aziende (oltre 10.000 pagine univoche) con contenuti che cambiano molto spesso (ogni giorno).
- Siti con una porzione consistente di URL totali classificati da Search Console come Rilevata, ma attualmente non indicizzata.
Contattaci per una consulenza SEO personalizzata
Perché il crawl budget è importante per la SEO
Secondo Google, il crawl budget dipende da diversi fattori, come la qualità del contenuto, l’autorità del dominio e la velocità di caricamento delle pagine. Un crawl budget adeguato permette a Google di scoprire e indicizzare nuove pagine in modo tempestivo, migliorando la visibilità complessiva del sito. Per ottimizzare il crawl budget, è consigliabile fornire una struttura di navigazione chiara e gerarchica, eliminare contenuti duplicati o non rilevanti e assicurarsi che le pagine importanti siano facilmente accessibili dai motori di ricerca. Inoltre, l’uso di file robots.txt (https://www.tuodominio.it/robots.txt)e sitemaps può aiutare a guidare il processo di crawling. Monitorare regolarmente il crawl budget e apportare eventuali modifiche necessarie può contribuire a migliorare l’efficienza dell’indicizzazione e l’esperienza degli utenti.
Dati sull’indicizzazione del sito
Per siti di grandi dimensioni è fondamentale sapere quante pagine di un sito sono indicizzate da un motore di ricerca, saperlo permette di:
- individuare quali parti importanti del sito non sono ancora indicizzate
- conoscere più a fondo i siti dei competitors e le relative strategie controllando quante delle loro pagine sono indicizzate.
Per visualizzare quante pagine sono indicizzate di un determinato sito basta usare il seguente comando “site: + nomedominio + estensione”sulla barra di ricerca di Google o Bing, ad esempio: site:key-one.it

Teoria generale della scansione
Google si impegna a scandagliare l’intero web, ma ha una capacità limitata. Questo limite, denominato “budget di scansione”, è determinato da due componenti principali: il limite di capacità di scansione e la domanda di scansione. Il primo assicura che Googlebot non sovraccarichi i server del sito, mentre il secondo si riferisce al tempo che Google è disposto a dedicare alla scansione del sito basandosi su vari fattori, tra cui la frequenza di aggiornamento e la qualità dei contenuti.
Vediamo nello specifico come funzionano i motori di ricerca. I motori di ricerca come Google utilizzano tre processi di base per catalogare le pagine Web: scansione, indicizzazione e posizionamento.
- Scansione: ricerca di informazioni: i crawler dei motori di ricerca iniziano visitando i siti Web dal loro elenco di indirizzi Web ottenuto da scansioni precedenti e mappe dei siti, fornito da vari webmaster tramite strumenti come Google Search Console. I crawler utilizzano quindi i collegamenti sui siti per scoprire altre pagine.
- Indicizzazione: organizzazione delle informazioni: successivamente, i crawler organizzano le pagine visitate indicizzandole. Il web è essenzialmente una gigantesca libreria che cresce ogni minuto senza alcun sistema di archiviazione centrale. I motori di ricerca visualizzano il contenuto della pagina e cercano segnali chiave che indichino di cosa tratta la pagina web (ad es. parole chiave). Usano queste informazioni per indicizzare la pagina.
- Classifica: informazioni sul servizio: una volta che una pagina Web è stata scansionata e indicizzata, i motori di ricerca forniscono i risultati delle query degli utenti in base all’algoritmo di classificazione con le pagine indicizzate.
Strategie per risparmiare il crawl budget e massimizzare l’indicizzazione
Prima di vedere come intervenire per risparmiare crawl budget bisogna sapere cos’è l’index to crawl ratio, ovvero il rapporto tra le pagine indicizzate e quelle che sono state scansionate. Se il bot ha effettuato il crawling su una pagina non è sicuro che questa verrà indicizzata. Solitamente, nei siti di grandi dimensioni, capita spesso che Google Search Console riporti un numero di pagine non indicizzate 2-3 volte superiore quello delle pagine indicizzata, come l’esempio sotto. In questi casi è evidente che sia presente un problema generale di indicizzazione. Una discrepanza così forte tra i dati riportati da GSC e le URL effettivamente disponibili nell’indice di Google potrebbe indicare la presenza di gravi problemi nei contenuti. In questi casi, infatti, Google si pone come missione verso i propri utenti di non rendere ricercabili ed accessibili URL che hanno contenuti troppo brevi (e quindi privi di valore) e contenuti duplicati.
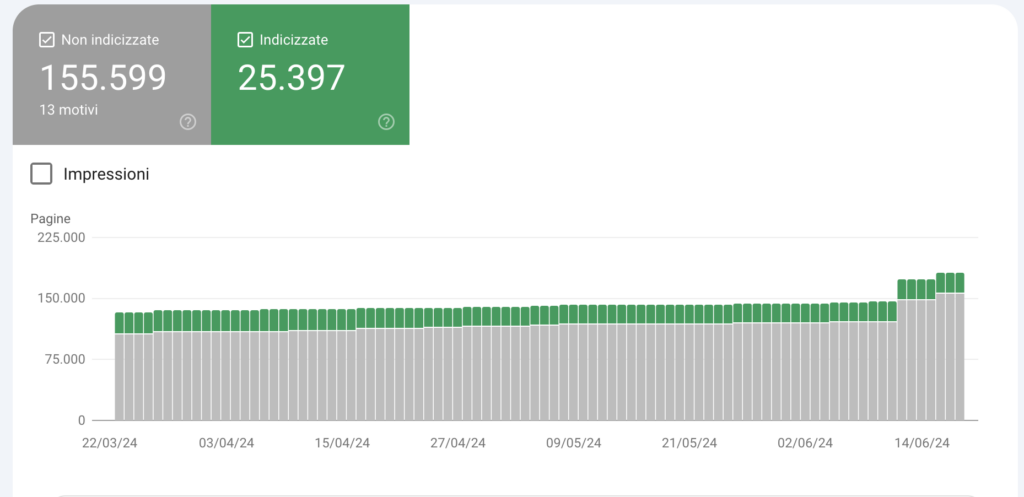
In questi casi, in fase di analisi, è fondamentale controllare che:
- non ci siano all’interno del sito pagine con contenuti duplicati;
- il rel canonical sia utilizzato in maniera corretta per indicare eventuali contenuti doppi all’interno di una pagina “genitore” e una “figlio”;
- le liste di redirect della famiglia 300 e 400 non siano troppo estese;
- controllare che non ci sia nessun motivo di natura tecnica che impedisca al crawler di Google di scansionare ed indicizzare le pagine, ad esempio tag noindex e nofollow nel codice;
- controllare che non ci siano indicazioni particolari di blocco nel file robots.txt e che non si stiano bloccando specifiche sezioni;
- controllare che ci siano sufficienti pagine con un numero minimo di parole, parliamo di almeno 170-250 parole per pagina evitando cosi i “thin content”.

Su siti di grandi dimensioni, il crawl budget può venire assorbito dalla scansione delle innumerevoli URL che sono poi rese inaccessibili a Google per vari motivi (legittimi e non), questo scatena il ritardo di indicizzazione dei contenuti appena pubblicati. Questo ritardo ha un impatto negativo molto forte per l’accesso delle notizie in Google News e Google Discover e pertanto si consiglia la risoluzione con priorità alta.
Best practice per ottimizzare la scansione
Per massimizzare l’efficienza della scansione di Google, è essenziale adottare alcune best practice. Gestire l’inventario di URL è di importanza critica: comunicare a Google quali pagine devono essere scansionate e quali no può prevenire lo spreco di risorse preziose. È utile anche accorpare i contenuti duplicati, bloccare la scansione di URL non cruciali tramite il file robots.txt e assicurarsi che le pagine rimosse restituiscano un codice di stato 404 o 410.
Altre raccomandazioni includono il mantenimento di Sitemap aggiornate, l’evitare lunghe catene di reindirizzamento e l’assicurarsi che le pagine si carichino in modo efficiente, per permettere a Google di leggere più contenuti del sito.
Contattaci per una consulenza SEO crawl budget personalizzata
Monitorare la scansione e l’indicizzazione del sito
Per tenere sotto controllo l’efficacia della tua strategia di scansione, è utile monitorare regolarmente il report Statistiche di scansione disponibile in Google Search Console. Questo report può aiutare a identificare problemi di disponibilità che impediscono a Google di eseguire una scansione efficace. È inoltre importante verificare che Googlebot non incontri ostacoli nella scansione di nuove o importanti pagine del tuo sito.
Strategie per la gestione di problemi specifici
Se si incontrano problemi nella scansione o si sospetta che Googlebot stia sovraccaricando il server del sito, è possibile adottare misure per mitigare questi problemi. Queste possono includere miglioramenti alla disponibilità del sito, modifiche alla configurazione del file robots.txt e ottimizzazioni delle performance di caricamento delle pagine. In casi eccezionali, se il sito è soggetto a una scansione eccessiva, può essere necessario intervenire per limitare temporaneamente l’accesso a Googlebot.
Inventario e pulizia di url: come risparmiamo crawl budget in Key-One
In Key-One, web agency di Milano, i SEO Specialist affrontano i problemi di scansione di grandi siti con analisi dettagliate al fine di pulire e ridurre la mole di url da sottoporre a scansione.
- Prima di tutto effettuiamo una scansione di tutti gli elementi di un sito usando strumenti come Screaning Frog che permettono di individuare tutte le url, i title, metadati e gli elementi che compongono il sito.
- Fatto questo analizziamo, robots.txt, Search Console e Google Analytics per farci un’idea su possibili macro errori.
- Fatto questo facciamo un’analisi incrociata di tutte le parole chiave posizionate del sito dalla prima alla 100 posizione della SERP (Search Engine Ranking Page) di Google, in questo modo possiamo avere una panoramica di tutte le url che hanno kws posizionate e con potenziale su cui andare a lavorare in ottica di ottimizzazione per recuperare eventuali posizioni.
- Questa analisi permette di non andare a eliminare pagine che portano già traffico organico o potrebbero portarlo in futuro. Anche le url con contenuti “evergreen”possono essere mantenute a prescindere dal fatto che portino traffico al momento dell’analisi, così come le pagine legate ad accordi commerciali e linkbuilding devono essere escluse dall’analisi di pulizia.
- Fatto questo le url non più utili e che “appesantiscono” il sito vengono passate in status code 404 o 410 che indica a Google la rimozione definitiva delle url avvisando i motori di ricerca di non perdere più tempo ad analizzarli.
- Un altro check è quello sulla velocità di caricamento degli elementi di una pagina e che questo venga fatto nella maniera più corretta tecnicamente.
- Un controllo che solitamente si fa su ecommerce di grandi dimensioni con migliaia di articoli come Arco e Frecce è nascondere le pagine a scorrimento orizzontale del carrello via robots.txt.
Crawl budget in caso di migrazione e restyling sito
Una fase particolarmente delicata di una migrazione del sito coincide con l’interazione con Googlebot, il crawler di Google responsabile dell’indexing delle pagine web. Durante questo periodo, è essenziale assicurarsi che Googlebot riconosca e segua i cambiamenti apportati al sito. Il consiglio è di procedere con un aggiornamento progressivo della sitemap del sito, segnalando così a Google le modifiche in atto. Questo passaggio permette ai gestori del sito di mantenere un certo livello di controllo su come e quando i nuovi contenuti o le modifiche strutturali vengono scoperti e indicizzati da Google, migliorando l’efficacia della migrazione.
Crawl budget: consigli tecnici per una migrazione efficiente
Affinché la migrazione del sito avvenga nel modo più fluido possibile, è fondamentale garantire il funzionamento ottimale di entrambi i server coinvolti nel processo, sia quello vecchio che quello nuovo. Assicurare la stabilità dei server significa prevenire crolli improvvisi o errori che potrebbero compromettere la reperibilità e l’efficacia del sito durante la transizione. Inoltre, una corretta impostazione dei redirect è cruciale per mantenere intatta la user experience e la valorizzazione SEO delle pagine vecchie che puntano alle nuove. Ultimo, ma non meno rilevante, è importante verificare che non ci siano risorse importanti inavvertitamente bloccate al crawler a seguito dell’aggiornamento del file robots.txt. La cura in quest’ultima fase è essenziale per non ostacolare l’accessibilità ai contenuti più rilevanti del nuovo sito.
Contatta i SEO Specialist di Key-One, agenzia digital di Milano, per una gestione ottimale del crawl budget del tuo sito
Dalla comprensione del concetto di crawl budget all’importanza di gestirlo in modo efficace, è chiaro che questa è una componente fondamentale per il successo della SEO. Le strategie per risparmiare il crawl budget e massimizzare l’indicizzazione sono cruciali per ottenere una visibilità ottimale sui motori di ricerca. Tuttavia, nonostante gli sforzi per gestire correttamente il crawl budget, ci sono ancora alcune criticità SEO legate a questo aspetto. Affrontare tali criticità richiede un’analisi attenta e una continua ottimizzazione delle pagine web. Il crawl budget è un argomento in continua evoluzione, con nuove sfide che emergono costantemente. Pertanto, è importante affidarsi a degli specialisti come il team di Key-one, agenzia digital di Milano, per adattare le strategie di ottimizzazione di conseguenza.
Contattaci per una consulenza SEO crawl budget personalizzata









